

Technical Highlights
- Bluetooth Version: Supports BT/BLE 5.4 dual protocol stack
- Audio Codec: Compatible with BLE Audio and LDAC, LC3 codec
- Noise Cancellation: Integrates hybrid Active Noise Cancellation (ANC) combining Feedforward (FF) and Feedback (FB) mechanisms
- Processing Power: Embedded with HiFi 5 Digital Signal Processor (DSP) and Neural Processing Unit (NPU) to support complex multi-microphone uplink noise reduction algorithms and keyword spotting in low power
- Supports Features: LE-Audio, Apple iOS FMD + Google FMD, Channel Sounding, multi-link mechanism connecting to two devices, Google Fast Pair, Spatial Audio, Native Wear Detect, PSAP, Low-Latency (upto 10ms)
T2M7034
The T2M7034 is a high-performance, feature-rich Bluetooth audio SoC designed for ultra-low power consumption and advanced TWS (True Wireless Stereo) applications. It supports BT/BLE 5.3, BLE Audio, and includes a HiFi 5 DSP along with an NPU (Neural Processing Unit) to enable efficient multi-microphone noise reduction and low-power keyword detection. The chip also integrates hybrid ANC (feedforward + feedback), making it suitable for headset designs that demand wideband and deep noise cancellation performance.
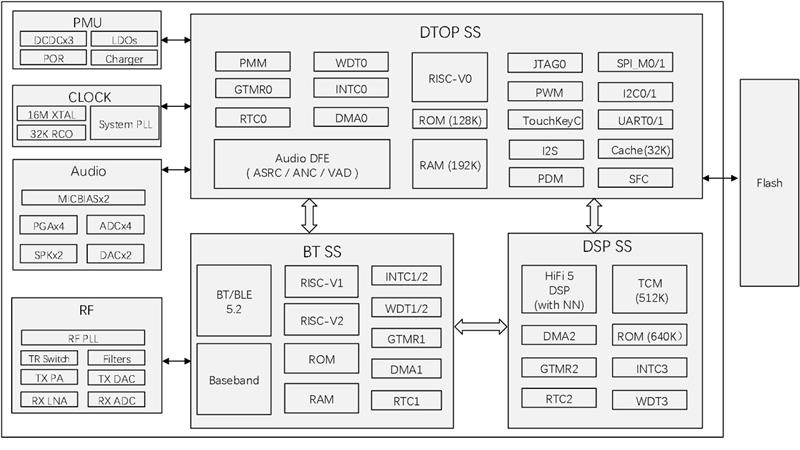
- Protocol: BT/BLE 5.3 + BLE Audio (BDR/EDR/LE 1M/2M/LE Coded 125K), supports TWS+
- MCU: RISC-V CPU with FPU, dynamic frequency 16–80MHz
- SRAM: 192KB RAM (MCU subsystem)
- Flash: Built-in 4MB Flash (supports XIP)
- Rich Interface: GPIO, UART×2, SPI×2, I2C×2, PWM×8, ADC×4, sensor hub, cap-touch
- Supply Voltage: 2.2V: 5.5V
-
Working Current:
- A2DP W-TWS: <4mA @ 3.8V (NOLOAD)
- A2DP + ANC: <6mA @ 3.8V (NOLOAD)
- Sleep Current: Deepsleep: <10µA @ 3.8V
- TX Maximum Power: Max 12dBm (BDR-1M), Max 10dBm (EDR-2M)
- RX Receive Sensitivity: -101dBm (BLE 1M), -107dBm (BLE 125K), -97dBm (BT BDR/EDR2M)
- Security Mechanism: OTA supported (based on SPP or GATT)
- Hybrid ANC (FF + FB) Support for strong and wideband noise cancellation
- HiFi 5 DSP + NPU Support for advanced multi-mic noise reduction and keyword recognition at low power
Applications
- TWS headset
- Gaming headset
- Stereo / Mono headset
- Wireless microphone
- Bluetooth adapter
Product Specifications
Product Selection Tool| Part No. | Protocol | MCU-MHz | SRAM (KB) | Flash (KB) | SPI | I2C | I2S | GPIO | UART | USB | ADC | Voltage | PKG | NODE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T2M7034A50 | BT / BLE 5.3, BLE Audio | 80 | 384 | 4096 | 2 | 2 | 1 | 11 | 2 | 0 | 14 | 2.2–5.5 V | QFN-50 4 × 6.4 | 22nm |
T2M7035
T2M7035 is a high-end Bluetooth audio SoC designed for premium, low-power wireless audio products. It supports dual BT/BLE 5.4 stacks along with BLE Audio, and integrates a HiFi 5 DSP and an NPU to efficiently run advanced algorithms such as multi-microphone uplink noise reduction, downlink audio effects, and adaptive active noise cancellation (ANC). The chip includes an adaptive hybrid ANC solution that delivers strong noise suppression with wide bandwidth and depth, while enabling real-time ANC adaptation for different environments. It also features a high-performance PMU with an integrated charger for precise power control and ultra-low power operation, and provides a five-channel capacitive sensing function to support touch control, in-ear detection, sliding gestures, and related applications, making it ideal for advanced TWS noise-cancelling headsets and other products requiring complex audio processing and voice AI features.
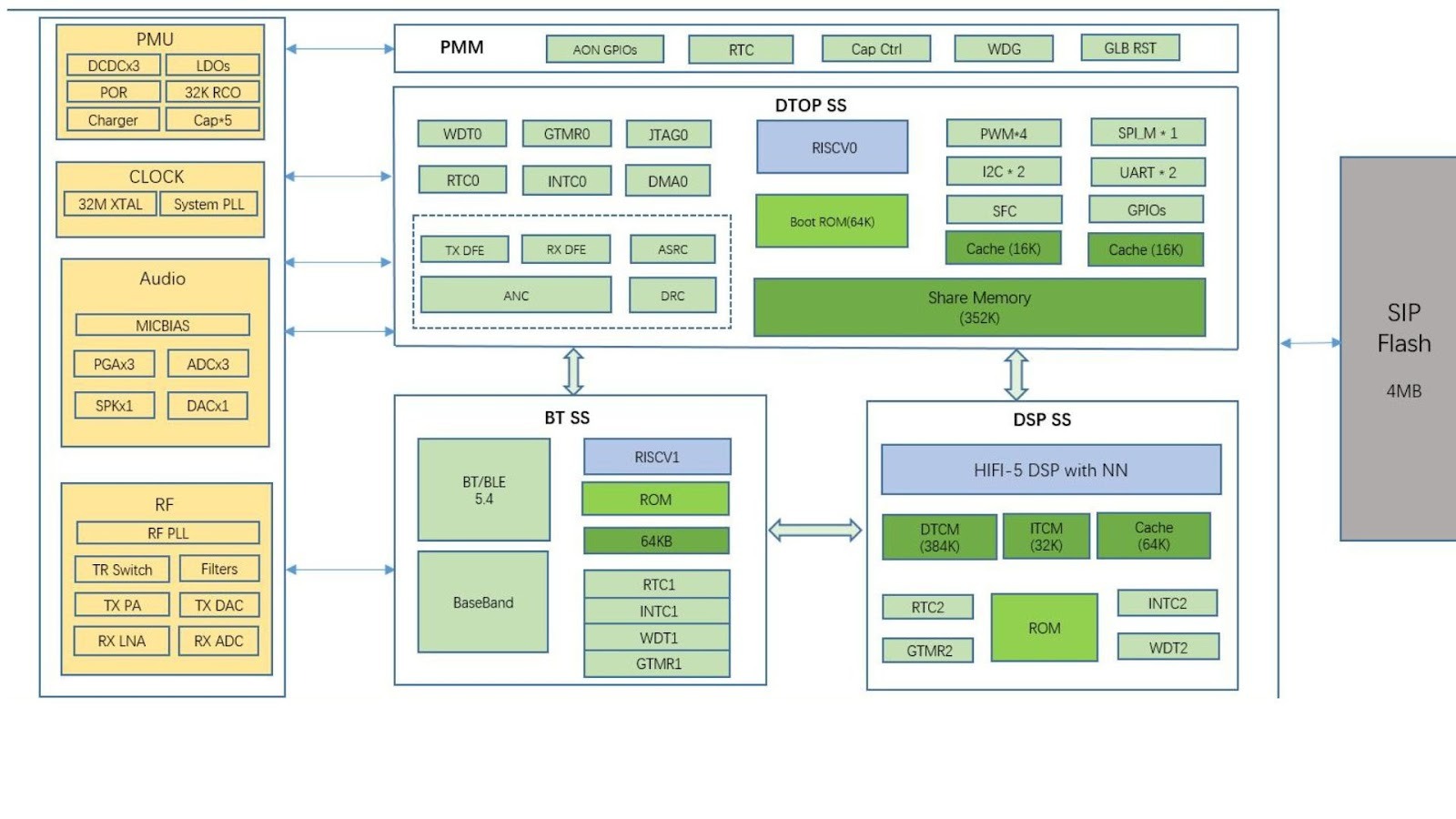
- Protocol: BT/BLE 5.4 dual stacks + BLE Audio (LC3)
- MCU: 32-bit RISC-V CPU (16–96MHz) + HiFi 5 DSP + NPU (DSP up to 192MHz)
- SRAM: 352KB shared memory + 64KB BT SRAM + DSP memory (32KB ITCM + 384KB DTCM)
- Flash: Built-in 4MB SiP Flash (XIP supported)
- Rich Interface: UART×2, SPI×2, I2C×2, GPIO (5 AON + 7 common), AuxADC×4, Capacitive sensor×5
- Supply Voltage: 2.2V 5.5V
- Working Current
- A2DP TWS: ~4mA @ 3.8V
- A2DP TWS + Hybrid ANC: ~5mA @ 3.8V
- Sleep Current: Deep sleep: <10µA @ 3.8V
- TX Maximum Power: Max 15dBm (BDR-1M), Max 11dBm (EDR-2M)
- RX Receive Sensitivity: -100dBm (BLE 1M), -97dBm (BLE 2M), -107dBm (BLE 125K)
- Security Mechanism: OTA supported (SPP- or GATT-based OTA)
- Adaptive Hybrid ANC (FF + FB)
- HiFi 5 DSP + NPU for advanced ENC / AI noise cancellation & voice algorithms
Applications
- Advanced TWS noise reduction headsets
- Low-power products requiring complex audio processing and voice AI
Product Specifications
Product Selection Tool| Part No. | Protocol | MCU-MHz | SRAM (KB) | Flash (KB) | SPI | I2C | I2S | GPIO | UART | USB | ADC | Voltage | PKG | NODE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T2M7035A52 | BT / BLE 5.4, BLE Audio | 96 | 352 | 4096 | 2 | 2 | - | 11 | 2 | 0 | 14 | 2.2–5.5 V | QFN-52 4 × 6.5 | 22nm |
T2M7036
T2M7036 is a premium Bluetooth audio SoC designed for high-performance and ultra-low power applications. It supports BT/BLE 5.4 protocol stacks along with BLE Audio, and integrates a HiFi 5 DSP and an NPU to efficiently run advanced functions such as multi-microphone uplink noise reduction and low-power keyword spotting. The chip also includes hybrid ANC (feedforward + feedback), making it suitable for headset designs that demand strong noise cancellation with wide bandwidth and depth. In addition, its high-performance PMU enables fine-grained power control for ultra-low power operation, and it offers multiple interfaces with flexible I/O mapping, making it ideal for advanced TWS noise-reduction headsets and other products requiring complex audio processing and voice AI capabilities.
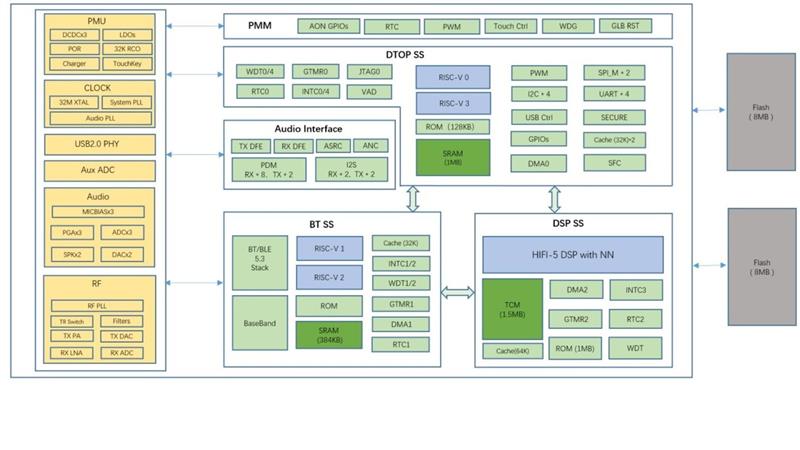
- Protocol: BT/BLE 5.4 + BLE Audio (LC3)
- MCU: Two 32-bit RISC-V CPUs (IMFC), 16–128MHz
- SRAM: 1MB SRAM
- Flash: Embedded 16MB NOR Flash (WQ7036AX)
- Rich Interface: USB2.0 device, UART, SPI, I2C, PWM (up to 8), GPIO (AON + common), Aux ADC, capacitive sensor
- Supply Voltage: 2.2V - 5.25V
-
Working Current
- TWS music playback: 4.5mA (typ.)
- TWS calling: 9mA (typ.)
- Sleep Current: Power-off with IO wakeup supported: ≤10µA
- Tx Maximum Power: Max 15dBm (BDR-1M), Max 11dBm (EDR-2M)
- Rx Receive Sensitivity: -100dBm (BLE 1M), -97dBm (BLE 2M), -107dBm (BLE 125K)
-
Security Mechanism:
- SPP- or GATT-based OTA
- Hybrid ANC (FF + FB)
- HiFi 5 DSP + NPU for multi-mic noise reduction & keyword spotting
Applications
- Mono headset
- Stereo headset
- TWS headset
- Mono speaker
- Stereo speaker
Product Specifications
Product Selection Tool| Part No. | Protocol | MCU-MHz | SRAM (KB) | Flash (KB) | SPI | I2C | I2S | GPIO | UART | USB | ADC | Voltage | PKG | NODE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T2M7036A129 | BT / BLE 5.4, BLE Audio | 128 | 1024 | 16348 | 2 | 4 | 4 | 41 | 4 | 1 | 14 | 2.2–5.5 V | BGA129 3.8 × 6.5 | 22nm |
T2M7037
T2M7037 is a high-performance Bluetooth Audio SoC designed for advanced low-power audio and voice AI applications. It supports Bluetooth / BLE 6.0 dual-mode operation and BLE Audio, integrating a high-performance DSP with NPU, multi-core RISC-V CPUs, and a highly efficient power management subsystem. The chip is optimized for premium TWS earbuds, active noise cancellation (ANC), AI-based noise reduction, and other audio-intensive, battery-powered devices while maintaining ultra-low power consumption.
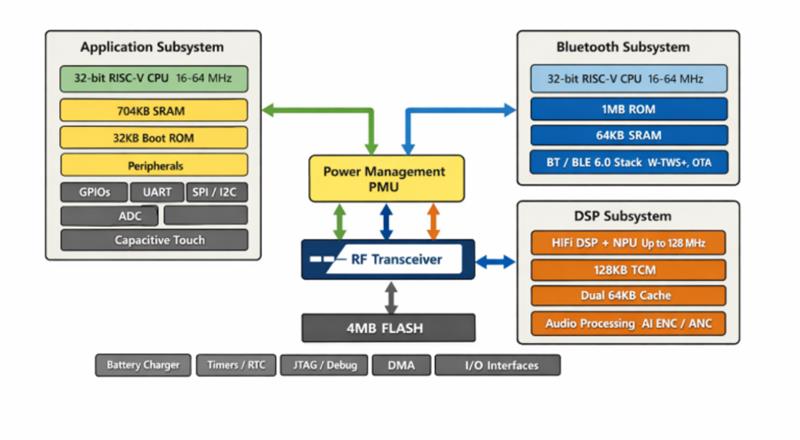
- Protocol: Bluetooth® / BLE 6.0 dual-mode (BDR / EDR / LE-1M / LE-2M / LE-Coded), BLE Audio (LC3)
- MCU: Dual 32-bit RISC-V MCUs + High-performance DSP with NPU
- SRAM: ~ 768 KB total (shared + dedicated SRAM, DSP TCM & cache)
- Flash: 4 MB embedded flash, supports XIP
- Rich Interfaces: UART, SPI, I²C, GPIO, ADC, Capacitive Touch, DMA, RTC, JTAG
- Supply Voltage: 2.2 V - 5.5 V
- Working Current: ~ 4 mA (A2DP TWS), ~ 8.5 mA (HFP + AI ENC)
- Sleep Current: < 7 µA (Deep Sleep)
- TX Maximum Power: Up to +15 dBm
- RX Receive Sensitivity: up to –106 dBm (BLE Long Range)
- Security Mechanism: Bluetooth standard security (pairing, bonding, encryption), secure OTA
Applications
- Premium TWS earbuds
- Active Noise Cancellation (ANC) headphones
- AI noise-reduction headsets
- Bluetooth voice assistants
- Smart wearable audio devices
- Low-power voice-enabled IoT products
- Advanced wireless audio accessories
Product Specifications
Product Selection Tool| Part No. | Protocol | MCU-MHz | SRAM (KB) | Flash (KB) | SPI | I2C | I2S | GPIO | UART | USB | ADC | Voltage | PKG | NODE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T2M7037A46 | Bluetooth Classic + BLE 6.0 (Dual Mode, BLE Audio) | 96 | 704 | 4096 | 2 | 2 | - | 11 | 2 | 0 | 14 | 2.2–5.5 V | QFN46 3.6 × 5.3 | - |
All Part Numbers
Global Search
| Series | Supplier Part No. | Protocol | MCU-MHz | SRAM (KB) | Flash (KB) | SPI | I2C | GPIO | USB | ADC | Datasheet |
|---|---|---|---|---|---|---|---|---|---|---|---|
| T2M7034 | T2M7034A50 | BT / BLE 5.3, BLE Audio | 80 | 384 | 4096 | 2 | 2 | 11 | 0 | 14 | N/A |
| T2M7035 | T2M7035A52 | BT / BLE 5.4, BLE Audio | 96 | 352 | 4096 | 2 | 2 | 11 | 0 | 14 | N/A |
| T2M7036 | T2M7036A129 | BT / BLE 5.4, BLE Audio | 128 | 1024 | 16348 | 2 | 4 | 41 | 1 | 14 | N/A |
| T2M7037 | T2M7037A46 | Bluetooth Classic + BLE 6.0 (Dual Mode, BLE Audio) | 96 | 704 | 4096 | 2 | 2 | 11 | 0 | 14 | N/A |